高途一面
自我介绍
项目介绍
什么是GC
释放那些不再使用的对象所占用的内存。GC首先要判断对象是否一个被收集,常用判断是否被收集的两种方法为
- 引用计数法:给对象添加引用计数器,每当有引用它的地方,就将计数器+1,当引用失效后,引用计数器-1,当计数器为0时,可以进行回收。
- 可达性分析法:扫描堆中的对象,看是否能够沿着GC Root对象为起点的引用链找到该对象,找不到则可以进行回收。
垃圾回收器
- 串行垃圾回收器(serial):也就是单线程回收器,在进行垃圾回收工作的时候,要暂停其他线程,直到它收集结束。新生代采用复制算法,老年代采用标记-整理算法。
- 缺点是:STP时间太长,用户体验不佳
- 优点是:简单高效,没有线程之间的开销
- ParNew回收器(多线程回收器):除了使用多线程进行垃圾回收外,其余的与单线程回收器一样。
- Parallel Scavenge(吞吐量优先回收器):并行收集器,高效率的利用cpu,吞吐量就是CPU用于运行用户代码的时间与CPU总消耗的时间比值。垃圾回收器并行工作(多条收集线程并行工作,但用户线程仍然处于等待状态)。
- CMS收集器(响应时间优先):并发收集器(指⽤户线程与垃圾收集线程同时执⾏(但不⼀定是并⾏,可能会交替执⾏),⽤户程序在继续运⾏,⽽垃圾收集器运⾏在另⼀个 CPU 上)以最短回收停顿时间为目标的收集器,注重用户体验,整个过程分为四步骤:
- 初始标记:暂停其他线程,记录直与root相连的对象,速度很快。
- 并发标记:GC和用户线程同时执行,由于用户线程会不断的更新引用域,所以GC无法达到可行性分析的实时性,
- 重新标记:为了修正并发标记期间用户程序运行改变的标记,
- 并发清除:开启用户线程,同时GC线程开始对未标记的区域做清扫。
使用标记-清楚会产生大量的碎片,但并发标记,低停顿。
- G1:同时注重吞吐量和低延迟,会将堆划分为多个大小相等的区域。
垃圾回收算法
OSI七层模式
- 应用层:为计算机用户提供服务
- 表示层:数据处理(加密,解密,压缩的)
- 会话层:管理(建立,维护,重连)应用程序之间的会话
- 传输层:为两台主机之间的通信提供通用的数据传输服务
- 网络层:路由和寻址,决定数据在网络的游走路径
- 数据链路层:帧编码和误差纠错
- 物理层:比特流传输
hashmap底层
数据库的事务性
线程的创建方式
(1)继承Tread类,步骤:
(1)创建一个继承于Thread的子类
(2)重写Thread类的run()方法—-》将此线程执行的操作声明在run()方法中
(3)创建继承于Thread的子类的对象
(4)调用start()方法(该方法作用:①启动当前线程 ②调用当前线程的run())
(2)实现Runnable接口,步骤:
(1)创建实现Runnable接口的类
(2)实现类去实现Runnable中的抽象方法:run()
(3)创建实现类的对象
(4)将此对象作为参数传递到Thread类的构造器中,创建Thread类的对象
(5)通过Thread类的对象调用start()
(3)实现Callable接口,步骤:
(1)创建一个实现Callable接口的实现类。
(2)实现call方法,将此线程需要执行的操作声明在call中
(3)创建实现Callable接口的实现类的对象
(4)将该对象传递到FutureTask构造器中,创建FutureTask对象
(5)将FutureTask对象作为参数传递到Thread类的构造器中,创建Thread对象,并调用start方法。
(6)如果要获取call方法的返回值时,则使用futureTask.get();则不使用。
(4)线程池的方式创建线程
1 | |
好处:
(1)提高响应速度(减少创建新线程的时间)
(2)降低资源的消耗(重复利用线程池中的线程,不需要每次都创建)
(3)便于线程管理:
corePoolSize:核心池的大小
maximumPoolSize:最大线程数
keepAliveTime:线程没有任务时最多保持多长时间会终止
线程池了解吗
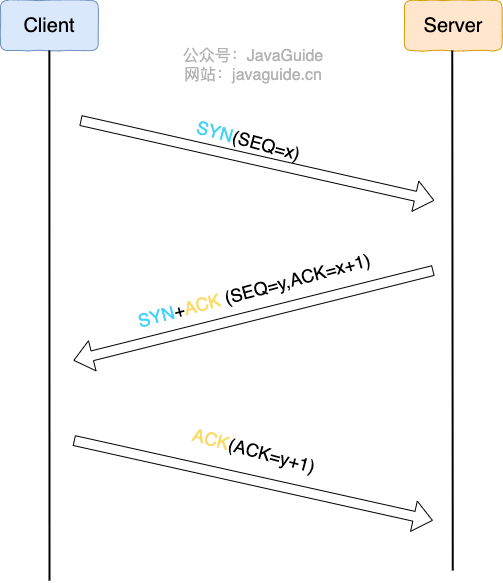
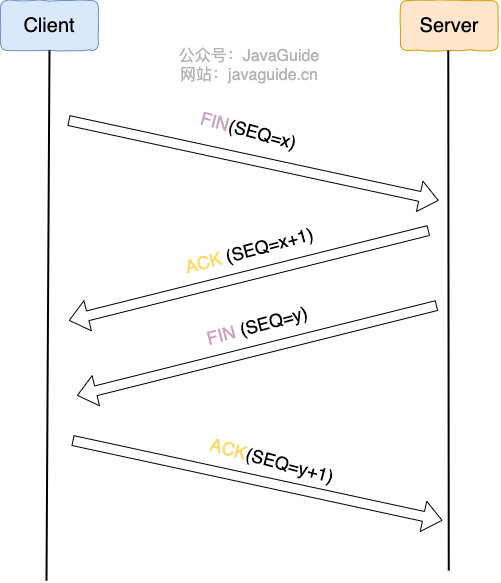
TCP的3次握手和4次挥手
SpringBoot比Spring好在哪里
(1)全部采用注解的方式,没有繁琐的xml配置文件
(2)快速整合第三方框架:
说一下IOC和AOP
项目中用没用到过AOP
项目中哪里用到了事务
操作两张表的时候,保证了事务的一致性,要么全成功,要么全失败,
例如:
(1)添加套餐这个操作,既要添加套餐这个表,也要添加套餐与菜品的关联表,因此要加入@Transactional注解,来保证要么加入两张表都成功,要么加入两张表都失败。
(2)提交订单时,要操作两个表,一个时订单表,和订单明细表,因此要使用事务。